In the previous article, we saw how machine learning generally works. The idea is to find an approximate mathematical function that can map the input variables into the output variable.
But there is a catch: both the inputs and outputs have to be numbers. On the other hand, an LLM takes text as input and returns text as output. Therefore, we need some mechanism to convert text into numbers.
The process to do this is called tokenisation. Let's see how it works
There are two techniques we can use to do tokenisation. One way is to assign a number for every letter (plus few more numbers to represent space, punctuations etc).
So we can say a has the value 1 and b has the value 2 and so on. Each of these numbers is called a token. The list of all possible values is called the vocabulary. The vocabulary here is the 26 letters for which we assigned numbers plus a few more for special characters.
Using this scheme, the word hello would be represented by a list of numbers [8, 5, 12, 12, 15]
This scheme has the advantage of having a very small vocabulary size, but it has a major disadvantage: It is very hard to understand meaning. Meaning is associated with words and not individual letters. Therefore, we need to be able to analyse combinations of tokens to understand meaning, which is a complex problem.
Another approach could be to assign numbers to full words themselves. So maybe the word hello gets the number 1 and the word goodbye gets the number 2. Continue this for all the words in the language.
This scheme has the advantage that a whole sentence can be represented with a handful of tokens. Even better, since a token represents a complete word, an individual token has a meaning associated with it.
The downside? You guessed, it: Every unique word needs a separate token and languages have hundreds of thousands of words. That is a giant vocabulary size. And what do you do if you encounter a new or unknown word?
The same dichotomy arises in written scripts. In logographic scripts, like most east asian scripts, there is a separate 'glyph' to represent each word. Thus, if you can read the glyphs, you can understand the meaning even if you don't know how to pronounce the word.
Phonetic scripts, like most Indic scripts, assign a glyph for every sound that you can make. If you can read the script, you can pronounce every word perfectly, even if you never understand it's meaning. Smaller vocabulary size, but less connection to the meaning.
And then you have English written in latin script, which is none of the above and even humans cannot make head or tail of it 😂 (joking, but not joking)
In practise, we take an approach that is in-between the two. There is an algorithm to break down words into pieces and each piece is a token and gets a number. This approach gives the best trade-off between vocabulary size, ability to understand meaning and also the ability to tokenise new or unknown words.
Example
Note that the exact tokenisation scheme varies from model to model, as data scientists keep experimenting and updating the algorithms.
We will explore OpenAI's GPT-4 tokenisation scheme here. OpenAI has a playground where you can see the tokenisation in action. Click the link below to open it 👇🏾
https://platform.openai.com/tokenizer
When you open the link, you will get a textbox where you can enter your text, and the page will show how it was tokenised, with each token in a separate colour.
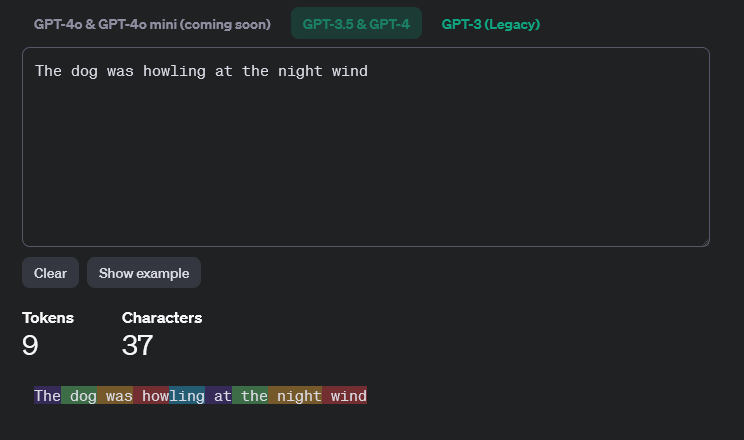
Couple of things to notice: First, notice how howling has been tokenised into two tokens, how and ling. Second, notice how the space in included in the token of the next word. dog without a space before it is a different token and dog with a space before it is a separate token. This reduces the number of tokens required in common sentences.
The site will also show us the exact token numbers used in GPT-4.

There is a button under the output that allows us to switch between text and token ID output. Select the token ID output and we can see the token numbers that get assigned in the case of GPT-4.
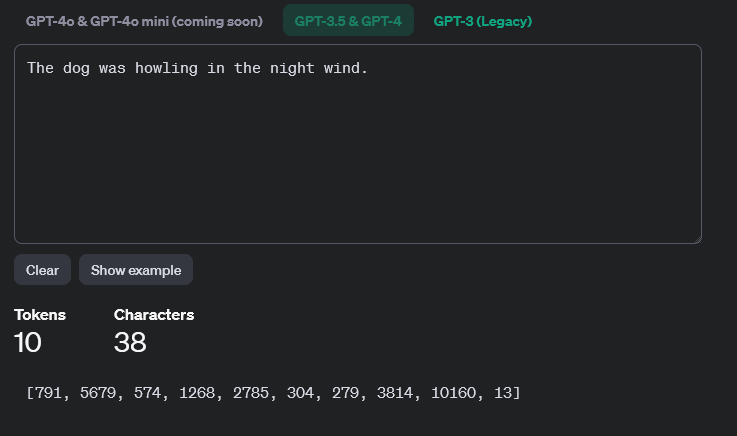
As we can see above, the sentence is represented by the list of tokens [791, 5679, 574, 1268, 2785, 304, 279, 3814, 10160, 13]
Try it out with different sentences, punctuation, nonsensical words and see how it tokeniser handles it!
Remember how we read in the news about how many tokens a model can process? For example, the recently released Claude 3.5 has a context window of 200K tokens. Since single words can be broken into multiple tokens, and punctuation also contributes to tokens, the actual number of words that the LLM can process is a little less.
In LLMs, a token is the unit of measure and not a word
Summary
Tokenisation is the process of taking text and representing it as a sequence of numbers. Remember, machine learning algorithms can only deal with numbers!
Now that we have tokens to represent the text, how do we assign meaning to the tokens? We will examine that in the next article.
Did you like this article?
If you liked this article, consider subscribing to this site. Subscribing is free.
Why subscribe? Here are three reasons:
- You will get every new article as an email in your inbox, so you never miss an article
- You will be able to comment on all the posts, ask questions, etc
- Once in a while, I will be posting conference talk slides, longer form articles (such as this one), and other content as subscriber-only