In the previous post, we talked about Big-O notation. In that article, we made the case that it is important to understand some aspects of how data structures work in Python, so that we can make the right choices when we code. If you haven't read that post, it is linked below
In this article, we start on the journey of understanding python data structures by taking a look at python lists.
Array Lists
There are two main ways to implement lists: As arrays and as Linked Lists. Python list datatype is implemented as an array, so lets take a look at that now, and we'll come back to linked lists later in the article.
An array is a continuous block of memory that can be allocated. We can then fill that memory with various values. So lets say we need to store three objects in a list, we could allocate 24 bytes – 8 bytes per reference in a 64 bit system – to store the references to the objects, plus a little more to store a few other things like the length of the list.
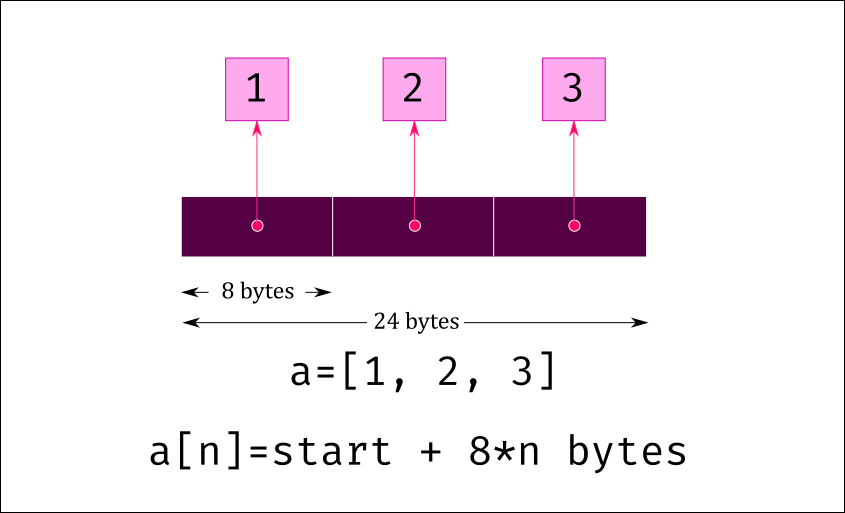
This has two advantages. First, we can access any value extremely fast. The memory is all continuous, so if we have a reference to the starting value of the list, we can calculate where the data for any index is stored and read that memory location directly.
Secondly, when iterating an array, you will get a lot of cache hits, which improves performance. I will say here that unlike languages like C, where significant optimisation is done to maximise cache hits, Python is not intended to be a high performance language and has many more overheads compared to the performance gain from a cache hit, but this is still nice to have.
There is a serious disadvantage though: What if you need to append a new item at the end of the list? Then, we need to allocate a bigger chunk of memory, copy all the existing data into there and finally add the new item at the end.
This is a lot of work, and extremely slow!! You don't want to be doing this every time an item is appended.
Therefore what usually happens is that we will allocate a chunk of memory more than the initial size of the list. That way, we will be able to append a few items before we run out of memory. When that chunk gets full, we allocate a bigger chunk of memory and copy over all the data to the new memory, leaving space for some more future items to be appended. The downside is we will end up allocating more memory than required, but the advantage is that we have to resize the memory much less frequently

There is another problem: If you want to add an item in the middle of the list – or even worse at the start – then you need to copy over all the existing data by a spot and make space for the new data to be inserted.
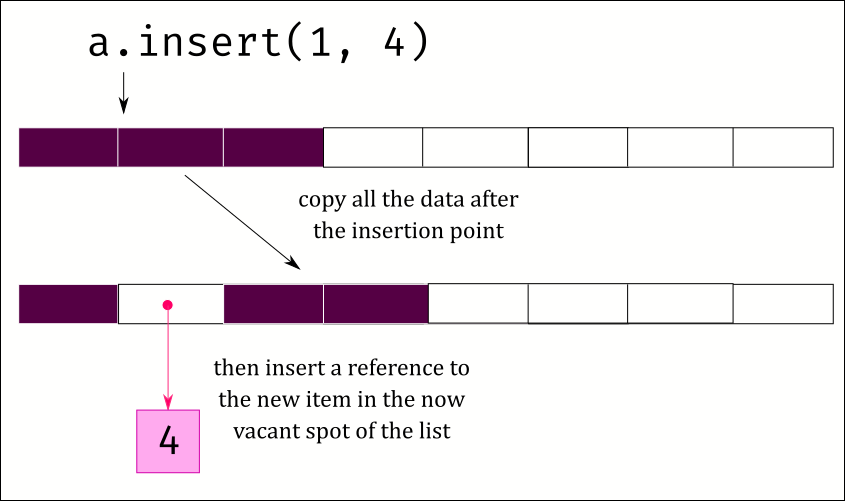
The same dynamic plays out when you need to delete an item from the list. Deleting the last item in the list is easy, just reduce the length of the list by one. But if you want to delete an item from the middle or the start, then you need to copy over all the following items to cover the gap.
Lets summarise array lists as implemented in python:
✅ Fast to access any element in the list
✅ Fast to add or remove an item at the end of the list
❌ Slow to add or remove items from the middle or start of the list
collections.deque
The natural next question to ask is whether python provides any data structure that can be used when you need to often add / remove items from the start of the list. The answer to this question is yes, and the data structure that provides this is called deque (pronounced 'deck') and it is in the collections module.
deque stands for double ended queue. It is a list type structure that supports fast inserts and deletes on both ends of the list (hence, double ended). It does this by using a linked list implementation. Let us take a look at how linked lists work.
Unlike an array, you don't allocate continuous memory for storing all the data. Memory is allocated for a single item, plus a reference to the next item. When another item is added at the end, memory is allocated for it, and the previous item is made to point to the new item.
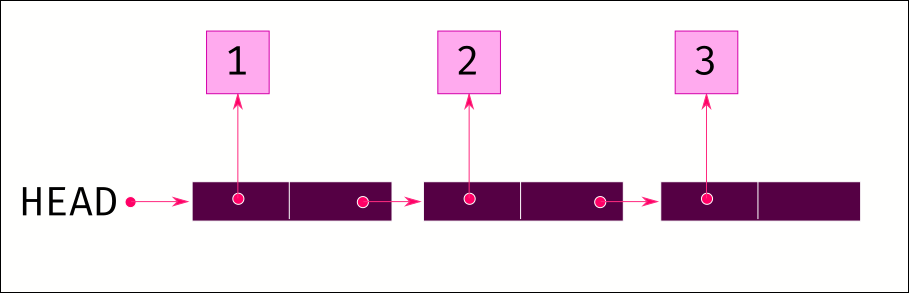
With a linked list, you don't have the situation where you run out of pre-allocated chunk of memory and need to resize and copy all the data over. Also inserting in the middle is easy; just allocate the memory for the new item and adjust the references to point to the items in the right order. No bulk copying of data.
It does come with a couple of disadvantages though. First, you cannot directly jump to any element. You need to start at the beginning of the list and iterate to the required position in the list. So item access, especially to the end of the list is slow. And following on from that, append to the end of the list is slow because it has to start at the head and iterate all the way to the last item before adjusting the references.
This can be mitigated to an extent by using a double linked list. A double linked list contains references to both the start and end of the list. Each item also contains references to the previous and next items in the list. This enables us to directly jump to the end of the list, and we can easily iterate both backwards and forwards.
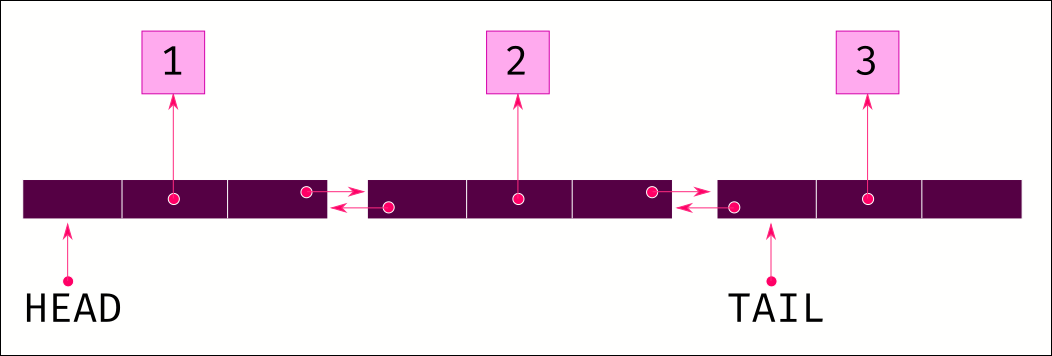
As usual, there is a tradeoff for this behaviour. Each item now needs 3 references: one for the previous item, one for the next and one for the data itself. In other words, every item in the list takes triple the amount of memory compared to a normal array list.
The python implementation of deque mitigates this by going with a hybrid solution. Each chunk stores multiple items in continuous memory, like an array list, but then chunks are linked together like a linked list. This gives a compromise between all the tradeoffs.
To summarise, the deque is:
✅ Fast to add / remove items from the start and end of the list
❌ Slow to access a random element in the list, especially around the middle
Which to use? A list or a deque?
Now that we have a better understanding of both data structures, we can decide when we need a list versus a deque.
Most of the time you would go with the ordinary list as it provides good characteristics for the three most common operations that most people use a list for: appending items, accessing random elements in the list, and iterating the list in order. While a deque is also fine for iterating in order, the list can take small advantage of the CPU cache by storing data in consecutive memory locations.
When you need to often insert or remove items at both endes of a large list, then turn to collections.deque. A first-in-first-out queue where you add items to the end of a queue and process and remove items from the start is a perfect use case for deque. Also, if you frequently need to insert or delete items from different places in the list, then a deque might be a better choice.
What about the array module?
Python also comes with an array module. What does this module do differently? Lets take a look.
Here is the image of python list from the beginning of the article
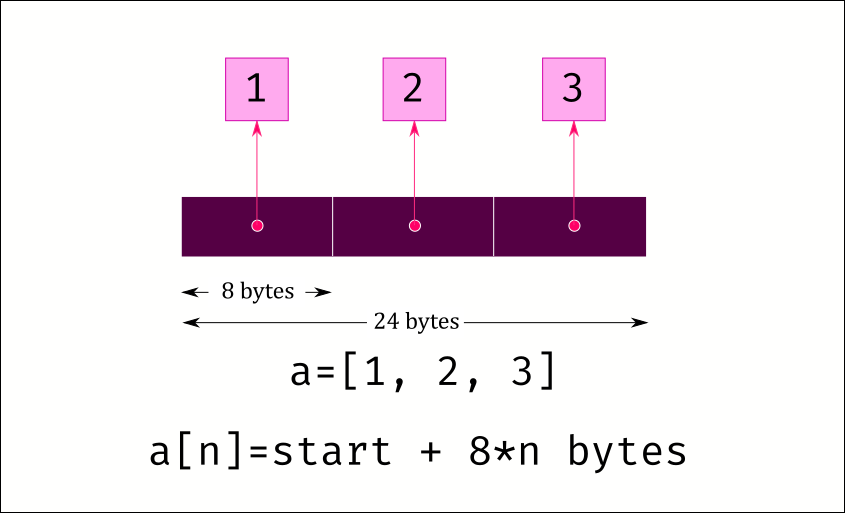
We learnt that storing data in successive memory locations improves performance because the CPU will read ahead some data and store it in the cache. So if we read the first 8 bytes to access the first element, the CPU will also read the values of the subsequent bytes and put it in the cache. If we next read the next item, the CPU will get that value from its internal cache instead of having to travel across the motherboard and read it from RAM.
There is a small problem though. The problem is that a list only stores object references. To get the actual object, you need to make another memory read to the place pointed to by the reference. This location is somewhere else in memory and will not be in the cache. This is known as a cache miss.
Consider this code:
a = [1, 2, 3]
for value in a:
print(value)Each time we do print(value), python will have to retrieve the object and it will result in a cache miss.
One option around this is to change the design such that the list stores the actual value instead of references to the object. Something like this

And that is exactly what the array module allows us to do. We can define an array with some values and those values are stored directly in the list memory locations itself. Now when we iterate the array, we can directly read the numbers. And all the values will end up in the CPU cache.
Thats nice, bute there are some significant disadvantages too.
- For one, each element in the array must be the same number of bytes. Only then can python jump to specific locations in the array.
- Secondly, object in python have some metadata, like its type and garbage collection information. The
arraymodule stores the values directly without this metadata, so you need to tell the array module what datatype you are storing, and all elements in the array should be only of that datatype. You cannot mix datatypes like you can in a normal python list - Thirdly, there is a list of supported datatypes, and you can only create an
arrayof one of these types
Here is what its like to use the array module
import array
a = array.array('b', [1, 2, 3, 4, 5])
for item in a:
print(a[item])There is one problem with the array module. When any item is accessed, it needs to take the value from the array, make an int object and return it, because the rest of python cannot work with a bare value, it only works with objects. This kind of operation is called 'boxing' and can be a significant overhead. Similarly, if you add any data to the array, it needs to take the python int object, extract the bare value in it, and store it in the array. This reverse operation is 'unboxing'.
Consider this code
a[2] = a[2] + 1This requires taking the raw value of a[2] from the array and making it an int object. Then we add 1 to it. Then to store it back into the array we have to extract the number from the output object and store it in memory.
Lets summarise the array module:
✅ Efficient storage of numeric data
❌ Need to box and unbox any time you perform operations on the data
Any other options?
Ideally, we would like to perform operations on the numbers without undergoing this overhead of boxing and unboxing.
Is there a way we can pack the data directly in the list and also perform calculations with the data without having to convert it back and forth between the bare value and python objects?
Yes there is, but you would have to use a third party module - numpy.
numpy provides its own array structure that packs data in this efficient way and also provides a number of operations that you can perform without needing to go back and forth between the raw numbers and python objects. When doing operations on giant arrays of numbers, all those CPU cache hits really add up and you can get massive performance boosts – making it a perfect fit for data science where we need to do exactly that
import numpy as np
a1 = np.array([1, 2, 3])
a2 = np.array([4, 5, 6])
a3 = a1 + a2In the code above, the numbers in the two arrays will be taken in the raw form and added up without converting them into python objects. The result will be stored in another numpy.array again without needing to unbox the numbers.
On the other hand, code like this will be terrible in numpy because it requires boxing and unboxing at each calculation an foregoes all the benefits of numpy
a1 = np.array([1, 2, 3])
a2 = np.array([4, 5, 6])
a3 = np.array([val1 + val2 for val1, val2 in zip(a1, a2)])Using numpy effectively is a huge topic on its own that we won't get into here. Suffice to say that if you need efficient numeric calculations then you should use numpy, but be careful to use it properly.
✅ Efficient storage of numeric data and maximising cache hits on the data
✅ Can do lots of operations on the data without boxing / unboxing
❌ Arrays restricted to certain data types
❌ Not optimised for inserting, deleting or performing calculations on data one value at a time (prefer doing calculations on all items in the array at once)
Summary
Thats a wrap up of this deep dive into python list and related data structures. Python provides us with many options apart from the usual list data type. In order to decide when to use each one, we need to understand how they all work, which is what we did in this article.
We went through four options: the regular python list, collections.deque, array.array and a popular third party option numpy.array.
Hopefully this article has given some insight into how these data structures work and when to use each one. The next time you look at a problem, you will be able to pick the right one for your needs, than just defaulting to the list.
Did you like this article?
If you liked this article, consider subscribing to this site. Subscribing is free.
Why subscribe? Here are three reasons:
- You will get every new article as an email in your inbox, so you never miss an article
- You will be able to comment on all the posts, ask questions, etc
- Once in a while, I will be posting conference talk slides, longer form articles (such as this one), and other content as subscriber-only